 | 教授は以前、あるパラメータをプラス/マイナス反転させても、光学性能が同じ方向にしか変動しなかったら、Monte-Carlo法を採用するしかないって言いましたよね?? | |||||||||||||||||||||||||||||||||
 | はい。 | |||||||||||||||||||||||||||||||||
| 具体的には、どんな光学性能が対象になるんですか?? | |||||||||||||||||||||||||||||||||
| おそらく、幾何光学的な性能は通常の公差計算で事足りると思いますが、波動光学的な性能はMonte-Carlo法で処理するしかないと思います。 | |||||||||||||||||||||||||||||||||
| 波面収差が絡んでくるからですか?? | |||||||||||||||||||||||||||||||||
| そうですね。基本的に、レンズ設計する際には波面収差を最小化するように面形状を追い込んでいくので、最適解の状態からいろいろなパラメータを変動させたら、それがプラスだろうとマイナスだろうと、波面収差は劣化するしかありません。その典型がビームスポット径でしょう。 | |||||||||||||||||||||||||||||||||
| そうすると、ビームスポット径はMonte-Carlo法で議論するしかないわけですね。 | |||||||||||||||||||||||||||||||||
| そうなりますね。 | |||||||||||||||||||||||||||||||||
| Monte-Carlo法で計算するとき、いつも思うんですけど、どのくらいのサンプル数だったら正しい結果になるのか、よく分からないんですよね〜。 | |||||||||||||||||||||||||||||||||
| なるほど。しかし、それは問いの立て方に問題があります。 | |||||||||||||||||||||||||||||||||
| 問いの立て方?? | |||||||||||||||||||||||||||||||||
| では質問ですが、正しい結果というのは、どういう意味ですか?? | |||||||||||||||||||||||||||||||||
| ムムム。得られた結果の信用度というか、信頼性というか…。 | |||||||||||||||||||||||||||||||||
| ということは、「正しい」というのを数値化できそうですね?? | |||||||||||||||||||||||||||||||||
| そうか。確かに、サンプル数が少なければ、得られた結果の信頼性は0に近いし、サンプル数が\(\infty\)なら信頼性は100%と言えそうです。 | |||||||||||||||||||||||||||||||||
| サンプル数は\(\infty\)でなくてもいいですね。母集団と同じサンプル数なら、得られた結果の信頼性は100%と言っても構わないでしょう。 | |||||||||||||||||||||||||||||||||
| そうすると、正しい問いの立て方は、どのくらいのサンプル数だったら、どのくらい信用できる結果が得られるのか、ってこと?? | |||||||||||||||||||||||||||||||||
| そうなります。つまり、「信用」がサンプル数の関数として数値化されると考えることができるのです。 | |||||||||||||||||||||||||||||||||
| でも、その関数の定義がないと、数値化できませんよ?? | |||||||||||||||||||||||||||||||||
|
では、こんなことを考えてみましょう。正規分布の母集団から\(n\)個のデータを抽出して、
| |||||||||||||||||||||||||||||||||
| たぶん、いろいろな値を取り得るんじゃないかなぁ。 | |||||||||||||||||||||||||||||||||
| 逆に、\(n\)が大きいと?? | |||||||||||||||||||||||||||||||||
| 1つの値に収束するように思えます。そうか。ということは、集合\(s\)のばらつきを指標にすれば、「信用」の定式化ができそうですね。 | |||||||||||||||||||||||||||||||||
| それも1つの考え方ですが、この場合、集合\(s\)のばらつきを、集合\(s\)の期待値で割った値を使うといいですね。これを変動係数(\(\rm CP\))と言います。 | |||||||||||||||||||||||||||||||||
| 何で期待値で割るんですか?? | |||||||||||||||||||||||||||||||||
| \(\rm CP\)が無次元の数値になるからです。 | |||||||||||||||||||||||||||||||||
|
てことは、集合\(s\)の期待値を\(\mathbb{E}\left[ s \right]\)、標準偏差を\(\mathbb{D}\left[ s \right]\)とすると、 \[ {\rm CP}=\frac{\mathbb{D}\left[ s \right]}{\mathbb{E}\left[ s \right]} \tag{1} \] ってこと?? | |||||||||||||||||||||||||||||||||
| はい。それを求めることがゴールになります。 | |||||||||||||||||||||||||||||||||
| いきなり求まりますか?? | |||||||||||||||||||||||||||||||||
| 少し準備が必要ですね。まず、\(\chi^2\)分布について見ていきましょう。 | |||||||||||||||||||||||||||||||||
〜\(\chi^2\)分布〜
| \(\chi^2\)分布?? | |
|
ここに、母平均\(\mu\)、母分散\(\sigma\)の母集団があり、そこから無作為に確率変数を\(n\)個だけ抽出します。このとき、\(y={x_1}^2+{x_2}^2+\dots+{x_n}^2\)の従う分布を\(\chi^2\)分布と言うのです。Helmertにより発見された分布です。 Friedrich Robert Helmert(1843〜1917) | |
| どんな分布になるのか、イメージが湧かないですね…。 | |
|
\(\chi^2\)分布の\(n\)を自由度と言いますが、この確率密度関数は\(n\)によって変化します。例えば、\(n=2\)として、\(y={x_1}^2+{x_2}^2\)の分布を考えてみましょう。10万個の\(y\)をヒストグラムで表示すると、図1のようになります。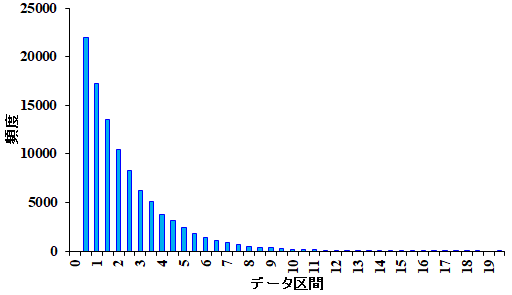 図1.自由度2の\(\chi^2\)分布 | |
| 単調に減少してますね。 | |
|
ところが、\(n=4\)として、同じく10万個の\(y\)をヒストグラムで表示すると、図2のようになります。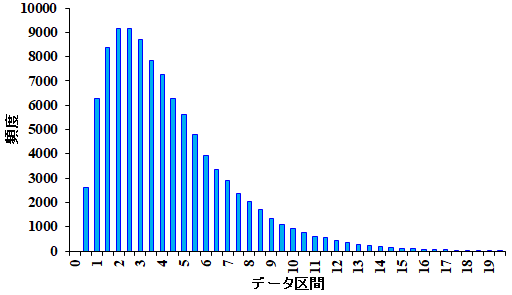 図2.自由度4の\(\chi^2\)分布 | |
| お〜、かなり様子が違いますね。 | |
| \(n\)が大きくなると、正規分布に近づいていくことが知られています。 | |
| これ、式で表したら、一筋縄ではいかなそうですね。 | |
|
そのとおりです。この確率密度関数は、\(y>0\)として、 \[ f_n\left(y\right)=\frac{1}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)}y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}} \tag{2} \] と表せます。 | |
| え〜。何ですか、これ。訊くんじゃなかった〜。 | |
|
\(\Gamma\left(z\right)\)はガンマ関数で、\(z\)は一般的には複素数です。 \[ \Gamma\left(z\right)=\int^\infty_0 t^{z-1}\mathrm{e}^{-t}dt \tag{3} \] | |
| 式(1)から式(2)を導出するなんて、とても思い付かないですけど。 | |
| しかし、式(2)であることは、数学的帰納法を用いれば簡単に証明できます。 | |
| 数学的帰納法かぁ。 | |
|
まず、\(n=1\)ですが、このとき式(2)は、 \[ f_1\left(y\right)=\frac{1}{2^{\frac{1}{2}}\Gamma\left(\cfrac{1}{2}\right)}y^{\frac{1}{2}-1}\mathrm{e}^{-\frac{y}{2}} = \frac{1}{\sqrt{2\pi}}y^{-\frac{1}{2}}\mathrm{e}^{-\frac{y}{2}} \tag{4} \] なので、式(4)になることを示せばよいことになります。 | |
|
ん?? \[ \Gamma\left(\frac{1}{2}\right)=\sqrt{\pi} \] ってこと?? | |
| それは式(3)を使って計算できますね?? | |
|
そっか。 \[ \Gamma\left(\frac{1}{2}\right)=\int^\infty_0 t^{\frac{1}{2}-1}\mathrm{e}^{-t}dt=\int^\infty_0 t^{-\frac{1}{2}}\mathrm{e}^{-t}dt \] ここで、\(t=s^2\)と置換すると、\(dt=2sds\)だから、 \[ \Gamma\left(\frac{1}{2}\right)=\int^\infty_0 s^{-1}\mathrm{e}^{-s^2}\times2sds=2\int^\infty_0 \mathrm{e}^{-s^2}ds \] ですね。 | |
|
そして、積分の部分はGauss積分の公式が使えるので、 \[ \int^\infty_0 \mathrm{e}^{-s^2}ds=\frac{\sqrt{\pi}}{2} \] です。 | |
|
だから、 \[ \Gamma\left(\frac{1}{2}\right)=2\times \frac{\sqrt{\pi}}{2}=\sqrt{\pi} \] になるわけか…。 | |
|
さて、正規分布の確率変数を\(X\)、自由度1の\(\chi^2\)分布の確率変数を\(Y=X^2\)としましょう。このとき、区間\(a\le Y\le b\)に含まれる確率\(P\left(a\le Y\le b\right)\)は、 \[ P\left(a\le Y\le b\right)=\int^b_a f_1\left(y\right)dy \tag{5} \] と書けます。これを、\(X\)で書き直すことを考えます。 | |
| 範囲から見直さないといけませんね。 | |
| どうなりますか?? | |
| う〜ん。\(a\le X^2\le b\)ってことだから、\(-\sqrt{b}\le X\le -\sqrt{a}\)か、\(\sqrt{a}\le X \le \sqrt{b}\)かな。 | |
|
そうすると、式(5)は、 \[ \begin{align*} P\left(a\le Y\le b\right)&=P\left(-\sqrt{b}\le X\le -\sqrt{a}\right)+P\left(\sqrt{a}\le X\le \sqrt{b}\right) \\ &=\int^{-\sqrt{a}}_{-\sqrt{b}} f\left(x\right)dx+\int^{\sqrt{b}}_{\sqrt{a}} f\left(x\right)dx \tag{6} \end{align*} \] と書き直せます。\(f\left(x\right)\)は正規分布の確率密度関数で、 \[ f\left(x\right)=\frac{1}{\sqrt{2\pi}}\exp\left[-\frac{x^2}{2}\right] \tag{7} \] です。 | |
|
これを式(6)に代入すればいいんですよね。 \[ P\left(a\le Y\le b\right)=\int^{-\sqrt{a}}_{-\sqrt{b}} \frac{1}{\sqrt{2\pi}}\exp\left[-\frac{x^2}{2}\right]dx+\int^{\sqrt{b}}_{\sqrt{a}} \frac{1}{\sqrt{2\pi}}\exp\left[-\frac{x^2}{2}\right]dx \] 正規分布は偶関数だから、右辺の第1項と第2項は等しくなって、 \[ P\left(a\le Y\le b\right)=\frac{2}{\sqrt{2\pi}}\int^{\sqrt{b}}_{\sqrt{a}}\exp\left[-\frac{x^2}{2}\right]dx \] になりそうですね。 | |
| ここで、\(x=t^{\frac{1}{2}}\)と置換します。 | |
|
そうすると、\(dx=\cfrac{1}{2}t^{-\frac{1}{2}}dt\)だから、 \[ \begin{align*} P\left(a\le Y\le b\right)&=\frac{2}{\sqrt{2\pi}}\int^b_a\mathrm{e}^{-\frac{t}{2}}\times\frac{1}{2}t^{-\frac{1}{2}}dt \\ &=\frac{1}{\sqrt{2\pi}}\int^b_a t^{-\frac{1}{2}}\mathrm{e}^{-\frac{t}{2}}dt \tag{8} \end{align*} \] 式(5)と式(8)の被積分関数を比較して、 \[ f_1\left(y\right)=\frac{1}{\sqrt{2\pi}}y^{-\frac{1}{2}}\mathrm{e}^{-\frac{y}{2}} \] 確かに、式(4)になりましたね。次は、\(n=k-1\)が成立するとき、って仮定するんですよね?? | |
|
はい。ここでは、これを次のように丁寧に言い換えてみましょう。 「\(Y={X_1}^2+{X_2}^2+\dots+{X_{n-1}}^2\)が自由度\(n-1\)の\(\chi^2\)分布に従うと仮定すると、\({X_n}^2\)が自由度\(1\)の\(\chi^2\)分布のとき、\(Y+{X_n}^2\)が自由度\(n\)の\(\chi^2\)分布に従う」ことを示す。 後半の「\(Y+{X_n}^2\)が自由度\(n\)の\(\chi^2\)分布に従う」というのをもう少し数学っぽく表現すると、「\(f_n\left(y\right)\)は、\(f_{n-1}\left(y\right)\)と\(f_1\left(y\right)\)の畳み込み積分で表される」となります。つまり、 \[ f_n\left(y\right)=\int^y_0f_{n-1}\left(t\right)f_1\left(y-t\right)dt \tag{9} \] ですね。右辺を変形してみてください。 | |
| え〜。途中で挫折しそうですけど…。 | |
| 挫折するところまででいいですよ。 | |
|
しょうがないなぁ。 \[ \begin{align*} \int^y_0f_{n-1}&\left(t\right)f_1\left(y-t\right)dt \\ &=\int^y_0\frac{1}{2^{\frac{n-1}{2}}\Gamma\left(\cfrac{n-1}{2}\right)}t^{\frac{n-1}{2}-1}\mathrm{e}^{-\frac{t}{2}}\frac{1}{2^{\frac{1}{2}}\Gamma\left(\cfrac{1}{2}\right)}\left(y-t\right)^{-\frac{1}{2}}\mathrm{e}^{-\frac{y-t}{2}}dt \\ &=\frac{\mathrm{e}^{-\frac{y}{2}}}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}\int^y_0t^{\frac{n-3}{2}}\left(y-t\right)^{-\frac{1}{2}}dt \tag{10} \end{align*} \] お手上げで〜す。 | |
| とりあえず、\(t=yu\)と置換してみましょうか。 | |
|
\(dt=ydu\)だから、 \[ \begin{align*} \int^y_0f_{n-1}&\left(t\right)f_1\left(y-t\right)dt \\ &=\frac{\mathrm{e}^{-\frac{y}{2}}}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}\int^1_0\left(yu\right)^{\frac{n-3}{2}}\left(y-yu\right)^{-\frac{1}{2}}ydu \\ &=\frac{\mathrm{e}^{-\frac{y}{2}}}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}\int^1_0y^{\frac{n-3}{2}}u^{\frac{n-3}{2}}y^{-\frac{1}{2}}\left(1-u\right)^{-\frac{1}{2}}ydu \\ &=\frac{y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}}}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}\int^1_0u^{\frac{n-3}{2}}\left(1-u\right)^{-\frac{1}{2}}du \tag{11} \end{align*} \] これ以上は無理です。 | |
|
ここから先は、特殊関数についての知識が必要です。まず、式(11)の積分ですが、これはベータ関数で表現できます。 \[ \int^1_0u^{\frac{n-3}{2}}\left(1-u\right)^{-\frac{1}{2}}du=B\left(\frac{n-1}{2},\frac{1}{2}\right) \tag{12} \] 更に、ベータ関数とガンマ関数の関係式から、式(12)は、 \[ B\left(\frac{n-1}{2},\frac{1}{2}\right)=\frac{\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}{\Gamma\left(\cfrac{n}{2}\right)} \tag{13} \] なので、式(11)は、 \[ \begin{align*} \int^y_0f_{n-1}&\left(t\right)f_1\left(y-t\right)dt \\ &=\frac{y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}}}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}\times\frac{\Gamma\left(\cfrac{n-1}{2}\right)\Gamma\left(\cfrac{1}{2}\right)}{\Gamma\left(\cfrac{n}{2}\right)} \\ &=\frac{1}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)}y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}} \tag{14} \end{align*} \] というわけで証明終わりです。 | |
| 教授。正規分布は常に平均が0、分散が1なわけではないですよ?? | |
|
その場合は標準化してください。つまり、式(7)は、 \[ f\left(x\right)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left[-\frac{\left(x-\mu\right)^2}{2\sigma^2}\right] \tag{15} \] となります。 | |
| その場合、\(\chi^2\)分布の確率変数も、\(y={x_1}^2+{x_2}^2+\dots+{x_n}^2\)ではダメですよね?? | |
|
そうですね。 \[ y=\frac{\left(x_1-\mu\right)^2}{\sigma^2}+\frac{\left(x_2-\mu\right)^2}{\sigma^2}+\dots+\frac{\left(x_n-\mu\right)^2}{\sigma^2} \] というふうに変更する必要があります。 | |
| なるほど。 | |
| ここで、標本の不偏分散\(s^2\)について改めて考えてみましょう。 | |
|
標本の不偏分散ということは、 \[ s^2=\frac{1}{n-1}\sum^n_{i=1}\left(x_i-\overline{x}\right)^2 \tag{16} \] ですか?? | |
| そうです。これを、母平均\(\mu\)を導入して変形します。 | |
| 導入??どういうこと?? | |
|
具体的には、 \[ x_i-\overline{x}=\left(x_i-\mu\right)-\left(\overline{x}-\mu\right) \] と変形するのです。 | |
|
ふ〜ん。そうすると、 \[ \begin{align*} s^2&=\frac{1}{n-1}\sum^n_{i=1}\biggl[\left(x_i-\mu\right)-\left(\overline{x}-\mu\right)\biggr]^2 \\ &= \frac{1}{n-1}\sum^n_{i=1}\biggl[\left(x_i-\mu\right)^2+\left(\overline{x}-\mu\right)^2-2\left(x_i-\mu\right)\left(\overline{x}-\mu \right)\biggr] \\ &= \frac{1}{n-1}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2+n\left(\overline{x}-\mu\right)^2-2\left(\overline{x}-\mu\right)\sum^n_{i=1}\left(x_i-\mu \right)\right] \\ &= \frac{1}{n-1}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2+n\left(\overline{x}-\mu\right)^2-2\left(\overline{x}-\mu\right)\left(n\overline{x}-n\mu\right)\right] \\ &= \frac{1}{n-1}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2+n\left(\overline{x}-\mu \right)^2-2n\left(\overline{x}-\mu\right)^2\right] \\ &= \frac{1}{n-1}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2-n\left(\overline{x}-\mu\right)^2\right] \tag{17} \end{align*} \] になります。 | |
|
式(17)は、両辺を\(\cfrac{n-1}{\sigma^2}\)倍すると、 \[ \frac{\left(n-1\right)s^2}{\sigma^2}= \sum^n_{i=1}\frac{\left(x_i-\mu\right)^2}{\sigma^2}-\frac{n\left(\overline{x}-\mu\right)^2}{\sigma^2} \tag{18} \] ですが、式(18)の右辺第1項は、標準正規分布の確率変数を2乗して、\(n\)個だけ足し合わせているので、自由度\(n\)の\(\chi^2\)分布に従うはずです。 | |
| お、確かに。 | |
|
一方、右辺第2項は、 \[ \frac{n\left(\overline{x}-\mu\right)^2}{\sigma^2}=\frac{\left(\overline{x}-\mu\right)^2}{\left(\cfrac{\sigma}{\sqrt{n}}\right)^2} \] というふうに変形すると、平均が\(\mu\)、分散が\(\cfrac{\sigma^2}{n}\)の標準正規分布の確率変数を2乗したものになっていると見ることができます。 | |
| ん??つまり、自由度1の\(\chi^2\)分布ってことかな?? | |
| そのとおりです。つまり、式(18)の右辺は、\(\chi^2\)分布の足し算になっているので、左辺も\(\chi^2\)分布であると言え、その自由度は\(\chi^2\)分布の再生性から\(n-1\)になるのです。 | |
| なるほど〜。 | |
|
そのことを、 \[ \frac{\left(n-1\right)s^2}{\sigma^2}\sim\chi^2_{n-1} \tag{19} \] と書いたりします。さて、ここでのゴールは式(1)を求めることでしたね?? | |
| うっ。ここまでの道のりが長すぎて忘れてました。そうすると、まずは\(\mathbb{E}\left[s\right]\)を求めたいですね。 | |
|
式(19)を、\(\chi^2\)分布の確率変数\(y\)と置くと、 \[ y=\frac{\left(n-1\right)s^2}{\sigma^2}\quad\Leftrightarrow\quad s^2=\frac{\sigma^2y}{n-1}\quad\Leftrightarrow\quad s=\sigma\sqrt{\frac{y}{n-1}} \] ですから、\(\mathbb{E}\left[s\right]\)というのは、 \[ \begin{align*} \mathbb{E}\left[s\right]&=\int^\infty_0sf_{n-1}\left(y\right)dy=\int^\infty_0\sigma\sqrt{\frac{y}{n-1}}\frac{1}{2^{\frac{n-1}{2}}\Gamma\left(\cfrac{n-1}{2}\right)}y^{\frac{n-1}{2}-1}\mathrm{e}^{-\frac{y}{2}}dy \\ &=\frac{\sigma}{\sqrt{n-1}}\frac{1}{2^{\frac{n-1}{2}}\Gamma\left(\cfrac{n-1}{2}\right)}\int^\infty_0y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}}dy \tag{20} \end{align*} \] を計算することに他なりません。 | |
| 他なりません、と言ったって…。これ、計算できないのでは?? | |
|
しかし、式(20)の被積分関数と式(2)を見比べてみると、そこはかとなく、\(2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)\)を演算したくなりませんか?? \[ \begin{align*} \mathbb{E}\left[s\right]&=\frac{\sigma}{\sqrt{n-1}}\frac{2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)}{2^{\frac{n-1}{2}}\Gamma\left(\cfrac{n-1}{2}\right)}\int^\infty_0\frac{1}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)}y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}}dy \\ &=\sigma\sqrt{\frac{2}{n-1}}\frac{\Gamma\left(\cfrac{n}{2}\right)}{\Gamma\left(\cfrac{n-1}{2}\right)}\int^\infty_0\frac{1}{2^{\frac{n}{2}}\Gamma\left(\cfrac{n}{2}\right)}y^{\frac{n}{2}-1}\mathrm{e}^{-\frac{y}{2}}dy \tag{21} \end{align*} \] 被積分関数は\(\chi^2\)分布の確率密度関数そのものですから、この積分は1になり、 \[ \mathbb{E}\left[s\right]=\sigma\sqrt{\frac{2}{n-1}}\frac{\Gamma\left(\cfrac{n}{2}\right)}{\Gamma\left(\cfrac{n-1}{2}\right)} \tag{22} \] となります。 | |
| 教授。眩暈がしそうです…。 | |
| 式(22)は、標本の標準偏差の期待値は、母集団の標準偏差に一致しない、よって標本の標準偏差は不偏推定量ではない、ということを意味します。 | |
| 標本の標準偏差は??何だか、他のパラメータなら不偏推定量になりそうな言い方ですね。 | |
| 不偏分散は、名前に「不偏」と付いているだけあって、不偏推定量ですよ。 | |
| 確認できますか?? | |
| 式(17)を使えば。 | |
|
式(17)か…。 \[ \mathbb{E}\left[s^2\right]=\frac{1}{n-1}\mathbb{E}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2-n\left(\overline{x}-\mu\right)^2\right] \tag{23} \] う〜ん。右辺第1項は、 \[ \mathbb{E}\left[\sum^n_{i=1}\left(x_i-\mu\right)^2\right]=\sum^n_{i=1}\mathbb{E}\left[\left(x_i-\mu\right)^2\right]=\sum^n_{i=1}\sigma^2=n\sigma^2 \tag{24} \] で合ってますか?? | |
| 合ってますね。 | |
|
よし。じゃ、次は第2項だな。 \[ \mathbb{E}\left[n\left(\overline{x}-\mu\right)^2\right]=\mathbb{E}\left[\left(\overline{x}-\mu\right)^2\right] \] えっと…。\(\left(\overline{x}-\mu\right)^2\)の期待値って、\(\overline{x}\)の分散と同じこと?? | |
| そうですね。 | |
|
そうすると、 \[ \begin{align*} \mathbb{E}\left[n\left(\overline{x}-\mu\right)^2\right]&=n\mathbb{E}\left[\left(\overline{x}-\mu\right)^2\right]=n\mathbb{V}\left[\overline{x}\right] \\ &=n\mathbb{V}\left[\frac{x_1+x_2+\dots+x_n}{n}\right] \\ &=n\times\frac{1}{n^2}\mathbb{V}\bigl[x_1+x_2+\dots+x_n\bigr] \\ &=\frac{1}{n}\biggl\{\mathbb{V}\bigl[x_1\bigr]+\mathbb{V}\bigl[x_2\bigr]+\dots+\mathbb{V}\bigl[x_n\bigr]\biggr\} \\ &=\frac{1}{n}\bigl\{\sigma^2+\sigma^2+\dots+\sigma^2\bigr\}=\sigma^2 \tag{25} \end{align*} \] でいいのかな。 | |
| 順調です。 | |
|
よしよし。そうしたら、式(24)と式(25)から式(23)は、 \[ \mathbb{E}\left[s^2\right]=\frac{1}{n-1}\left(n\sigma^2-\sigma^2\right)=\frac{n-1}{n-1}\sigma^2=\sigma^2 \tag{26} \] お、確かに一致した。 | |
| はい。つまり、標本の分散は不偏推定量であり、その場合は\(n\)で割るのではなく、\(n-1\)で割らなければならないことも理解できますね。 | |
| でも、標準偏差が不偏推定量じゃないなら、意味ないのでは?? | |
| そうですが、\(n\)が大きければ、\(\mathbb{E}\left[s\right]\approx\sigma\)は言えますからね。 | |
| 直感的にはそうですけど、式(22)を見ても、そうなる予感はしませんね…。 | |
|
それはガンマ関数があるからでしょう。ただ、ガンマ関数は、実数\(p\)が大きいとStirlingの近似が成立します。 \[ \Gamma\left(p\right)\sim\sqrt{2\pi p}\left(\frac{p}{\mathrm{e}}\right)^p \tag{27} \]  James Stirling(1692〜1770) | |
| それを式(22)に適用すればいいわけですね?? | |
|
そうです。少し一般性を持たせるなら、 \[ \Gamma\left(p+q\right)\sim\sqrt{2\pi\left(p+q\right)}\left(\frac{p+q}{\mathrm{e}}\right)^{p+q} \] の比を考えるといいですね。 \[ \begin{align*} \frac{\Gamma\left(p+q\right)}{\Gamma\left(p\right)}&=\frac{\sqrt{2\pi\left(p+q\right)}\left(\cfrac{p+q}{\mathrm{e}}\right)^{p+q}}{\sqrt{2\pi p}\left(\cfrac{p}{\mathrm{e}}\right)^p}=\sqrt{\frac{p+q}{p}}\left(\frac{p+q}{p}\right)^p\frac{\left(p+q\right)^q}{\mathrm{e}^q} \\ &=\left(1+\frac{q}{p}\right)^{p+\frac{1}{2}}\frac{\left(p+q\right)^q}{\mathrm{e}^q} \tag{28} \end{align*} \] ここで、式(28)の前半部分は、Napier数の定義から、 \[ \lim_{p\to\infty}\left(1+\frac{q}{p}\right)^{p+\frac{1}{2}}\rightarrow\mathrm{e}^q \] ですし、後半部分は、 \[ \lim_{p\to\infty}\left(p+q\right)^q\rightarrow p^q \] なので、式(28)は\(n\)が大きくなると、\(p^q\)に近づくことが分かります。 | |
|
ふむふむ。式(22)に適用させると、\(p=\cfrac{n-1}{2}\)、\(q=\cfrac{1}{2}\)とすればいいから、
\[
\frac{\Gamma\left(\cfrac{n}{2}\right)}{\Gamma\left(\cfrac{n-1}{2}\right)}\approx\left(\frac{n-1}{2}\right)^{\frac{1}{2}}
\]
となって、 \[ \mathbb{E}\left[s\right]\approx\sigma\sqrt{\frac{2}{n-1}}\times\sqrt{\frac{n-1}{2}}=\sigma \tag{29} \] ってことか。 | |
| これで式(1)の分母が求まりました。 | |
| 次は分子か…。何か道のりが遠いな…。 |
〜デルタ法〜
| デルタ法?? | |
| 聞いたことないですか?? | |
| ないですね〜。 | |
| これは、独立した確率変数\(X\)が平均\(\overline{X}\)、分散\(\varsigma\)の分布に従うとき、それを変数とした関数\(g\left(X\right)\)の平均、分散を近似的に求める方法のことです。 | |
| 関数の形は何でもいいんですか?? | |
| 連続微分可能であれば。ところで、関数の近似と言えば?? | |
|
Taylor展開が定番ですね。 Brook Taylor(1685〜1731) | |
| おそらく、確率変数\(X\)は平均\(\overline{X}\)の周りにまとわりついている分布になっているだろうから、\(g\left(X\right)\)を\(\overline{X}\)の周りでTaylor展開すると、よい近似になるのではないか、というのがデルタ法の発想です。 | |
| そう言われると、そんな気もしますね。 | |
|
\(g\left(X\right)\)はこのとき、 \[ g(X)=g(\overline{X})+\frac{g^{\prime}(\overline{X})}{1!}(X-\overline{X})+\frac{g^{\prime\prime}(\overline{X})}{2!}(X-\overline{X})^2+\cdots \] となるので、2次の項までで近似した期待値はどうなりますか?? | |
|
期待値は、 \[ \begin{align*} \mathbb{E}\bigl[g(X)\bigr]&\approx \mathbb{E}\bigl[g(\overline{X})\bigr]+\mathbb{E}\bigl[g^{\prime}(\overline{X})(X-\overline{X})\bigr]+\mathbb{E}\bigl[\frac{g^{\prime\prime}(\overline{X})}{2}(X-\overline{X})^2\bigr] \\ &=g(\overline{X})+g^{\prime}(\overline{X})\mathbb{E}\bigl[X-\overline{X}\bigr]+\frac{g^{\prime\prime}(\overline{X})}{2}\mathbb{E}\bigl[(X-\overline{X})^2\bigr] \\ &=g(\overline{X})+g^{\prime}(\overline{X})\mathbb{E}\bigl[X\bigr]-g^{\prime}(\overline{X})\mathbb{E}\bigl[\overline{X}\bigr]+\frac{g^{\prime\prime}(\overline{X})}{2}\varsigma^2 \\ &=g(\overline{X})+g^{\prime}(\overline{X})\overline{X}-g^{\prime}(\overline{X})\overline{X}+\frac{g^{\prime\prime}(\overline{X})}{2}\varsigma^2 \\ &=g(\overline{X})+\frac{g^{\prime\prime}(\overline{X})}{2}\varsigma^2 \tag{30} \end{align*} \] かな。 | |
| 1次の項までで近似した分散は?? | |
|
分散は1次の項まででいいのか…。 \[ \begin{align*} \mathbb{V}\bigl[g(X)\bigr]&\approx \mathbb{V}\bigl[g(\overline{X})\bigr]+\mathbb{V}\bigl[g^{\prime}(\overline{X})(X-\overline{X})\bigr]=\bigl\{g^{\prime}(\overline{X})\bigr\}^2\mathbb{V}\bigl[X-\overline{X}\bigr] \\ &=\bigl\{g^{\prime}(\overline{X})\bigr\}^2\mathbb{V}\bigl[X\bigr]-\bigl\{g^{\prime}(\overline{X})\bigr\}^2\mathbb{V}\bigl[\overline{X}\bigr]=\bigl\{g^{\prime}(\overline{X})\bigr\}^2\varsigma^2 \tag{31} \end{align*} \] これで、どう?? | |
| いいですね。以上がデルタ法の公式になります。さて、これから求めたいのは\(\mathbb{D}\left[s\right]\)ですが、これは分散\(\mathbb{V}\left[s\right]\)の平方根なので、\(\mathbb{V}\left[s\right]\)が求まればよさそうですね?? | |
| そうですね。 | |
| そこで、式(19)から議論をスタートすることにします。 | |
| \(\cfrac{\left(n-1\right)s^2}{\sigma^2}\)は自由度\(n-1\)の\(\chi^2\)分布に従う、というやつですね。 | |
|
\(\chi^2\)分布の分散は自由度の2倍ですから、 \[ \mathbb{V}\left[\frac{\left(n-1\right)s^2}{\sigma^2}\right]=2\left(n-1\right) \] です。 | |
|
そうすると、\(s^2\)の分散は求まりそうですね。 \[ \left(\frac{n-1}{\sigma^2}\right)^2\mathbb{V}\left[s^2\right]=2\left(n-1\right) \quad\Leftrightarrow\quad\mathbb{V}\left[s^2\right]=\frac{2\sigma^4}{n-1} \tag{32} \] だけど、ほしいのは\(\mathbb{V}\left[s\right]\)だからなぁ。 | |
|
そこで、デルタ法の登場です。式(29)を踏まえると、 \[ \overline{X}=\mathbb{E}\left[s\right]=\sigma \] ですし、 \[ \varsigma^2=\mathbb{V}\left[s\right] \] なので、式(30)は、 \[ \mathbb{V}\bigl[g(s)\bigr]=\bigl\{g^{\prime}\left(\sigma\right)\bigr\}^2\mathbb{V}\left[s\right] \tag{33} \] となります。 | |
| お、\(\mathbb{V}\left[s\right]\)が出てきましたね。 | |
| 式(31)を活用するには、\(g\left(s\right)\)はどんな関数だとよいですか?? | |
| う〜ん。\(g\left(s\right)=s^2\)だといいかも。 | |
|
そうすると、\(g^{\prime}\left(\sigma\right)=2\sigma\)だから、 \[ \begin{align*} \mathbb{V}\left[s^2\right]=\left(2\sigma\right)^2\mathbb{V}\left[s\right]\quad\Leftrightarrow\quad\frac{2\sigma^4}{n-1}=4\sigma^2\mathbb{V}\left[s\right]\quad\Leftrightarrow\quad\mathbb{V}\left[s\right]=\frac{\sigma^2}{2\left(n-1\right)} \tag{34} \end{align*} \] というふうに晴れて\(\mathbb{V}\left[s\right]\)が求まりました。 | |
|
んでもって、式(29)と式(34)から式(1)は、 \[ \rm{CP}=\frac{\mathbb{D}\left[s\right]}{\mathbb{E}\left[s\right]} =\frac{\sqrt{\mathbb{V}\left[s\right]}}{\mathbb{E}\left[s\right]} =\frac{\sqrt{\cfrac{\sigma^2}{2\left(n-1\right)}}}{\sigma} =\frac{1}{\sqrt{2\left(n-1\right)}} \tag{35} \] となるわけか。何か、物凄く議論したわりに、結果はしょぼいですね…。 | |
| しかし、最初に設定した問いに対する答えがこれです。例えば、サンプル数を100とすると、\(\rm{CP}\)はおおよそ7%、つまり統計処理した結果は7%の不確からしさを持っていることになりますし、サンプル数を1,000とすると、\(\rm{CP}\)はおおよそ2%、つまり統計処理した結果は2%の不確からしさを持っていることになります。 | |
| なるほど〜。そうすると、1,000個くらいで統計処理すれば充分そうですね。 | |
| そうですね。計算機のパワーが強ければ、もっと増やせばいいですし、そうでない場合、1,000個を統計処理すれば、そこそこ信頼できる結果になると言えそうです。 |
| 前頁へ | 戻る |